企业故障:服务器假死
一、事件发生
本来好好的写报告突然zabbix报警:
问题!新VPC监控
主机:XXXXXX;XXXXXX
地址:XXXXXX;XXXXXX
项目:Zabbix agent on XXXXX is unreachable for 5 minutes;
状态:PROBLEM;
级别:Average;
时间:2019.12.20_14:08:16
zabbix告诉我此主机5分钟没有响应,收到报警后立刻登录服务器,但是尴尬的是登录不上去,于是ping了一下,咦~发现可以ping同,说明服务器还没有正在的死掉,于是又通过百度云平台vnc进行连接,但是连接不上去,根据以上分析判断服务器假死,于是进行重启抓紧恢复。
二、事件排查
重启完之后服务器可以正常登录了,立刻先检查恢复线上业务,线上业务没问题后进行排查。
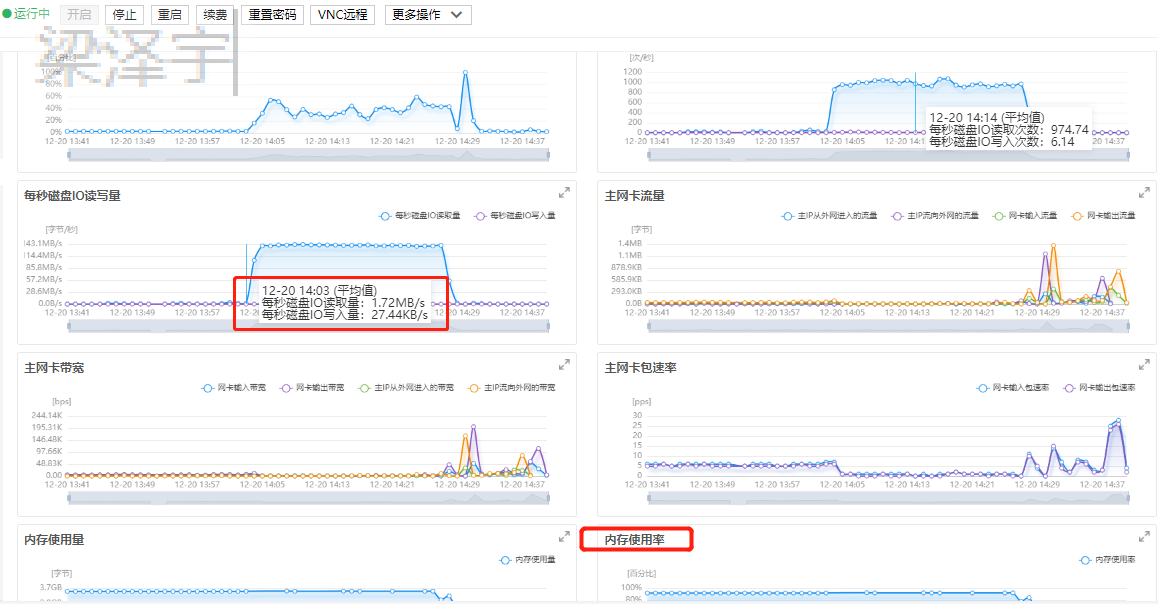
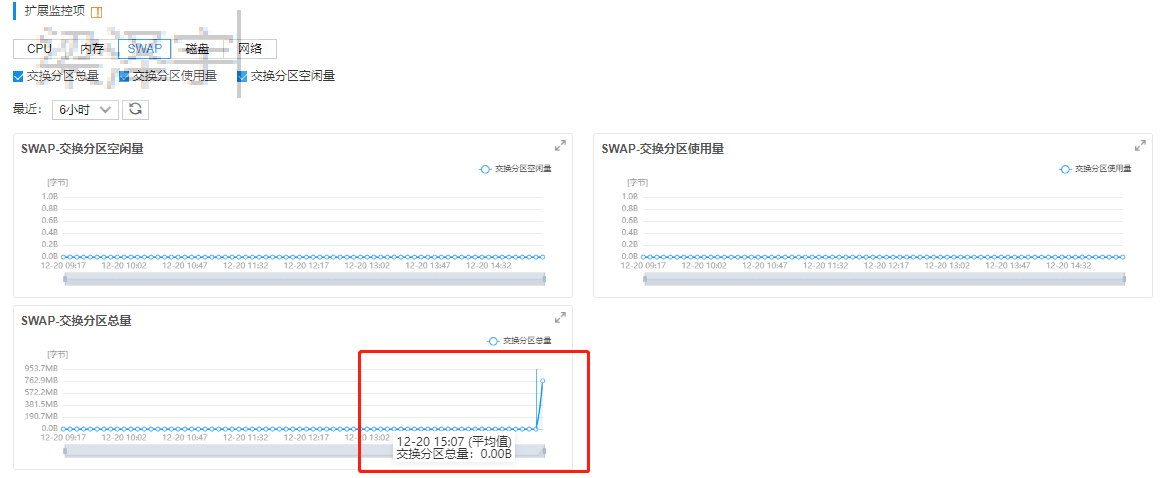
排查1:看到云后台的监控数据,发现12点20的时候io直接上涨,但是内存没有发生变化(一直都是80%以上),后来了解到内存过高会启用swap分区,这个时候就会把IO跑起来。然后在在后台看到了swap分区果然跑起来了。(先定位内存问题)(启动swap分区swapon /www/swap)(如果没有swap分区,内存跑满了就奔溃了。)
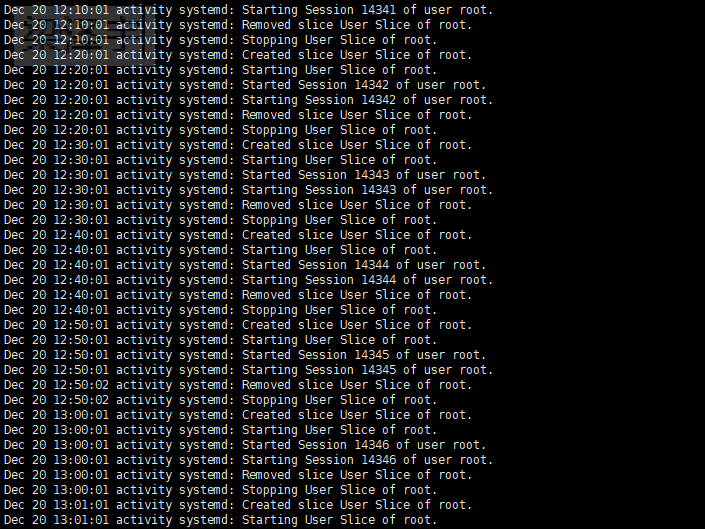
排查2、查看历史cpu、内存、负载、日志;
(1)/var/log/messges日志 无异常
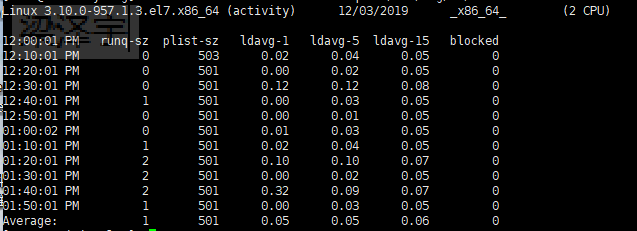
(2)sar -s 12:00:00 -e 14:00:00 -q -f /var/log/sa/sa03 查看历史负载 --无异常
(3)sar -s 12:00:00 -e 14:00:00 -f /var/log/sa/sa03 查看cpu 无异常

(4)sar -r -f /var/log/sa/sa29 查看内存 有异常
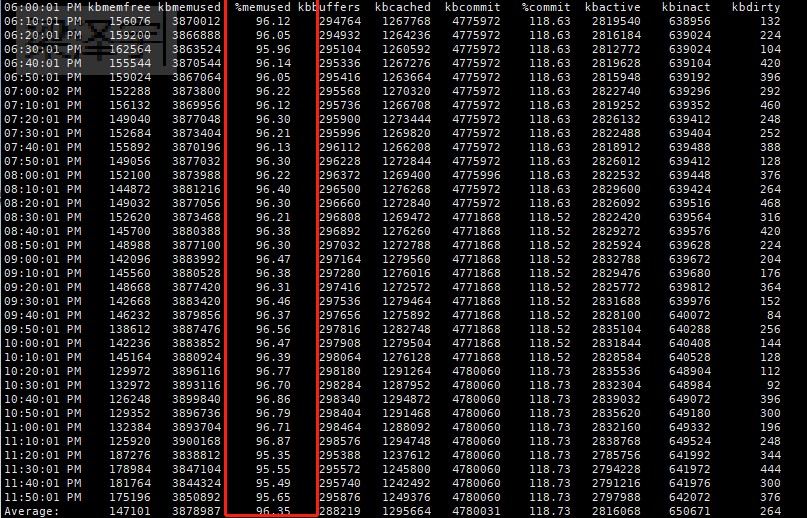
看到内存的问题之后看看服务器上面跑的什么业务,发现2核4G的服务器上面跑了docker+mysql+php+tomcat+nginx,然后看看了tomcat访问的日志,并没有发现什么访问量。
二、解决
1、对ssh设置nice值最大,这样服务器假死的时候也能ssh上去。
2、对swap分区加大。

有问题请加博主微信进行沟通!

全部评论